Note that this was written during large development in Quantum Computers, and when I was in high school. Both of these to say this won't be perfectly accurate
Introduction
Quantum computing is a key concept in computing, as it is a method which allows for far faster computing, beyond the current limits of classical computing. My question is: to what extent could quantum computers improve on classical computers. I chose this topic because of its relevance to the future of computing and the impact it can have on the world. I am particularly interested in it due to my future plans to study Computer Science at university and my interest in Physics.
I am going to explore this subject by finding out the key ways in which
quantum computers improve on classical computers, and compare the way a
quantum computer carries out a process compared to a classical computer.
After this I will compare the two methods, finding which is the best. I
will also compare the hardware of both quantum and classical computers,
comparing them and finding which scenarios each perform best in
Quantum computers are computers that work on a superposition of states,
rather than the 1 and 0 as classical computers do. This allows for them
to process data much faster due to more efficient algorithms able to
utilise the larger number of states, alongside quantum properties such
as entanglement. I will be comparing these to classical computers, which
have been developed over a much longer time, allowing for the most
efficient algorithms on that hardware to be created, however these can’t
be developed much further due to the physical limitations of classical
computers.
The Physics of Computers
The physics of classical computers
Transistors
Classical computers work using transistors, these are in effect electronic switches which will either permit or deny current through them based on the current in the third leg.

In this diagram the electrons are collected at the collector (C) and then taken into the N doped silicon. When electrons are provided to the base (B) they will flow into the P doped silicon. This will then cause electrons to flow from the collector to the emitter (E), producing a current.
Transistors and Logic Gates
Transistors can be arranged in many ways to produce logic gates. These are then used in various combinations to perform the mathematical operations that are used in classical algorithms.

Above is shown the NOT gate, constructed from transistors, the input, X, will be inverted to Y.

Above is the AND gate, this requires both X and Y to be on, in order for Z to be on. This is because when X is on it will provide current for Transistor 2, which will only transmit if Y is on.

Above is the OR gate, the collectors of the transistors are connected to the + node, so that whenever the base (X or Y) receives an input, it will give an output to the collector. The collector of both transistors are connected to the output, so if one or both of them is on the output will be on.
Moore’s Law
Moore’s law 1 states that: the transistor density of integrated circuits doubles every two years. This has held true for many years, however many argue that it will soon come to an end. The problem, which is the main limitation of classical computers, is the size that transistors can be made. Over many years the size has reduced, with recent processors having transistors of length around 10nm from collector to emitter. However, as the diameter of an atom is from 0.1 to 0.5nm, processor manufacturers will soon be unable to continue this miniaturisation. This could lead to an end to development in classical computers as if they can’t get any smaller they can’t get any faster.
The Physics of quantum computers
Introduction to Qubits
Qubits are the quantum equivalent of binary bits, they can take a combination of the ground state and the excited state. These states are derived from the energy states of electrons around a nucleus in current quantum computers, however in the future the nucleus could also be used. The power of a quantum computer over a classical one is due to the fact that it can take both of these simultaneously with different probability amplitudes (the square root of the probability that when measured it will be in that state).
Motion
Quantum computers work based on the spin of quantum particles2. These can be electrons but development is being made into using a nucleus as the qubit in a quantum computer. These electrons are usually held in a mechanism called an ion trap, this is where ions are kept in one place, so that measurements can be made on them. These ions are kept in one place by using high frequency voltage, this causes it to vibrate in approximately one place. This motion is further reduced as the centre of the defined range has very low motion, which the ion naturally tends to as it is the state of least energy.
Temperature
The next challenge is ensuring that the thermal energies3 in the processor are small compared to the energies in the operating of the processor. The problem with this is that when operating the processor, very low energies are used. This is because the kinetic energy gained when an ion emits or absorbs a photon is in the order of between and . The thermal energy inside the processor has to be less than this, requiring the temperature to be extremely close to absolute zero. In order to do this, the ion trap uses lasers. These cool the ions down as they provide energy in the direction opposite to their momentum, reducing overall energy. One of the largest problems in doing this is getting the correct frequency of light, this is because the ions will only be affected by the energy from the laser, if it is exactly the resonant frequency, this means that very precise lasers are required to cool the ions. One of the problems is ensuring that the lasers don’t add energy to the ions. This is solved by using the Doppler Effect, this is where an object moving towards a wave will experience it at a higher frequency. This is used in a quantum computer, by providing light at a slightly lower frequency than required. This means that ions moving towards it will experience the correct frequency, reducing their energy, but those moving away will not gain any energy.
Magnetic Field
All qubits have a spin, which is what is measured in a quantum computer. The side effect of the spin is it creates a magnetic field. The problem with this is that surrounding magnetic fields can change the spin. This magnetic field created by the spin is so weak that it can be changed by the earth’s magnetic field, the consequence of this is that a quantum computer can’t work under normal magnetic conditions. To solve this the quantum computer is electromagnetically shielded. This is done using many superconducting magnetic fields, a side benefit of having to cool the computer close to absolute zero. These counteract any incoming magnetic fields, protecting the qubits in the processor.
Control
To change the state of a qubit, it is illuminated by a laser, adding or reducing energy depending on direction relative to the movement of the qubit, changing the energy and so the state. However, the power of a quantum computer often comes from its ability to use two interacting qubits. To do this an XOR gate is required. The quantum version of an XOR gate is a CNOT gate, this flips qubit if qubit is equal to 1.
This works by exciting qubit in a way that it will become excited if its state is 1. The qubit is excited with too much energy, meaning that it starts to excite all the qubits in the system if qubit’s state was 1, meaning they require less energy to become excited. Qubit is then given less energy than if it was in a state unaffected by qubit, this means that it will not become excited if qubit wasn’t, but it will become excited if it was. To finalise the operation, qubit is given the same amount of energy as it was given originally, cancelling out the excitation it gave to all the qubits, putting all but qubit back in their original state.
Comparison
Quantum computers rely on much more volatile states than classical computer do. This means that there is much more control required. The consequence of this is that quantum computers are much harder to build and manage, as well as them only being able to be used in one place. This limits them compared to classical computers which are now small and portable so can be used anywhere. As with the early classical computers, it is likely that quantum technology will develop such that they can be miniaturised, however that is not currently available. However, quantum computers may not need to be portable as the current uses for them don’t require them to be moveable.
The physics of quantum computers is beneficial, in that it allows for the use of quantum algorithms. This can make the complexity in construction and maintenance worthwhile, however only in certain scenarios. It also could be argued that quantum computers are less complicated than classical computers as quantum computers are only used in certain cases, meaning that they only have a few thousand qubits, compared to classical computers which have transistors in the order of billions. This is partially due to the efficiency of quantum computing as, for example a NOT gate requires 2 transistors but only 1 qubit. Transistors are also of a larger size than qubits, meaning that more qubits can theoretically be placed in a given area. Quantum computers also have a larger potential for miniaturisation as they can be used with electrons, which are smaller than m, meaning that the limits of quantum computing are far smaller than the limits of quantum computing. This means that theoretically on a 3cmcm processor there could me more than qubits, far more than is possible with a regular CPU, which has around transistors (if each transistor was composed of 3 atoms, which is the limit of what is possible without a scientific breakthrough). This means that a quantum computer could have over a quadrillion times more processing units than the best classical computers in a given chip size.
Introduction to each method of operation
Quantum Computers
Qubit Notations
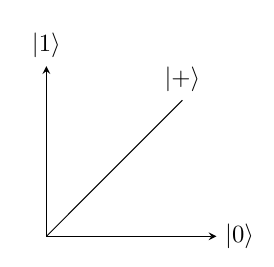
The notation for qubits may appear similar to binary notation, however the meaning of them is very different. For a single Qubit system, the measurement will be in the format [^alpha_beta]. Where is equal to and is equal to . The probability of the Qubit being measured as is and the probability of the Qubit being measured as is . These probabilities must add to 1 as there is a 100 chance it will be in one of the two states, this also means that the length of the vector is 1. This allows all quantum states to be expressed as points on a unit circle. An example of this is shown in figure 1, a representation of a vector in a Hilbert Space. This displays the state , denoted as . This makes a angle with each axis as the probability of each is equal.
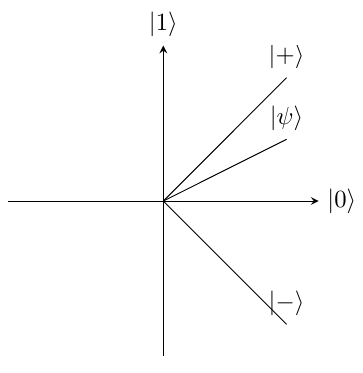
When the probability of each state is different, for example, the state . The angle with the axis is calculated by performing so, in this case, the angle is which is equal to an angle of .
The value of a Qubit can be measured with regards to and as shown above, but it can also be measured in terms of and where is equal to and is equal to . This is shown in Figure 2 which shows both the and the basis. This allows the state to be measured in either of them. The sign and bit value cannot both be known perfectly, this is because when measured, for example in the axis the superposition collapses and the value becomes 100 or . This means that if a second measurement in the basis was taken, the value would be different to the result if that was the first measurement. As an example, from the figure the state is most likely to be measured as as it makes the smallest angle with that axis. So when the value is then measured in the axis there is an equal probability of either. However, if that had been measured first it would be most likely to come as a as it makes the smallest angle with that axis.
Quantum Gates
There are many quantum gates, some are very similar to classical gates but some do functions that could not be performed on a classical computer.
Pauli X Operator
One set of quantum gates are the Pauli Operators 4, the Pauli X operator is shown by the 22 matrix:
This performs a similar function to the classical NOT gate and obeys the following truth table
| Input | Output |
|---|---|
The reason for this can be shown in the below calculation:
Pauli Y Operator
The Pauli Y operator performs both a bit and phase flip and is shown by the 22 matrix
The truth table of this gate is:
| Input | Output |
|---|---|
The reason for this is explained in the following calculation:
Pauli Z Operator
The Pauli Z operator performs a phase flip, this in effect changes the sign in front of the vector. It uses the following matrix.
This is very similar to the identity matrix and so will not change the absolute value of any of the bits. However, it will change the sign due to the negative sign on the bottom right hand value of the matrix above.
| Input | Output |
|---|---|
This can be shown in the following calculation:
The Hadamard Transform
The Hadamard transform creates an equal superposition of and . It does this using the matrix:
This creates the truth table:
| Input | Output |
|---|---|
How Classical Computers Work
Bit Notations
Binary bits have much simpler notations than Qubits as they take one definite state, either a 1 or a 0. Larger strings of these can be used to define larger states by each position taking values of powers of two, with the smallest bit position being equal to which is equal to 1. The next bit position will take which is equal to 2. Groups of bits are used to show data, for example the byte (8 bits) can contain different combinations, easily allowing for the Latin alphabet and numbers along with many other alphabets.
Classical Gates
Computers construct logic gates from transistors this means that a CPU made out of transistors can create combinations of these gates which can be used to process data. The main logic gates are the AND, OR, NOT and XOR, with extra gates with an integrated NOT gate like a NOR gate. The only one bit gate is the NOT gate, this will invert the input, and follows the following truth table:
| Input | Output |
|---|---|
| 0 | 1 |
| 1 | 0 |
The AND gate will only turn on if both inputs are on, and so follows the truth table in figure 4.
| Input 1 | Input 2 | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
The OR gate performs a similar function to the AND gate but will turn on the inputs if either of the inputs are on, as shown in the truth table in figure 5.
| Input 1 | Input 2 | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
The XOR gate is similar to the OR gate but will only turn on the output if only one output is on, following the truth table in figure 6.
| Input 1 | Input 2 | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Comparison between the two methods of working
The method of quantum computing compared to classical computing could be thought of as better due to its ability to take multiple states simultaneously. This means that operations can be performed on long strings of numbers represented in a superposition in one cycle. The same in classical computers would require one cycle for each value in a list.
However, the benefit of classical computers is the relative simplicity of the process, allowing for them to be more accessible. It also reduces the research and manufacture time as they are well documented as classical computers are much older inventions, with many experts in the field.
Deutsch-Jozsa algorithm
How the Deutsch-Jozsa Algorithm works
The Deutsch-Jozsa algorithm 5 is used to find if a quantum function is constant or balanced. A constant function will give one result for any input. A balanced function will give one result for half the inputs and another result for the other half.
The function will take an input and give an output of . To start this algorithm two qubits are needed, called and . The Pauli x operator is applied to to turn it from to . The Hadamard transform is then applied to both Qubits, turning into and into . These Qubits are then given to the quantum function, and because is equal to and v is equal to the output from the function to is . The Hadamard transform is then applied again to , giving the result . If the function is constant then f(0) = f(1) and because equals 2 if n is odd and -2 if n is even will always have a value if the function is constant. However always equals zero and so will not have a value. This means that if the function is constant will have a value of . However if the function is balanced with a one bit binary output only 1 and 0 are permitted. As equals zero but and . This means that for a balanced function
A classical alternative to the Deutsch-Jozsa Algorithm
The classical alternative to this algorithm would be to test the function with a maximum of half the range of the input numbers. Most times that range would not be necessary, as different output values would often come up earlier. If the function gives all one value it is constant but if two values are found it will be balanced.
Deutsch-Jozsa Algorithm compared to a classical method
The Deutsch-Jozsa algorithm can be considered to be superior to a classical algorithm, as it can find the correct solution with one query of the function, whereas classically it could take up to queries where n is the length of the input strings. Obviously for large number of bit inputs the Deutsch-Jozsa algorithm has far greater performance as it takes a constant number of queries, whereas classically it requires an exponential number of queries. However, the actual usefulness of either algorithm is severely limited as it can only be performed on quantum functions, a task not often faced in the current world.
Searching Algorithms
Binary Search
Binary search is a method used to find an item in an ordered list. It works by choosing the middle element of a list and checking if the desired item is before or after it and then discounting the other values based on this result. As shown below, when trying to find the value C with red being selections and strikeouts being removals.
| A | B | C | D | E | F |
| A | B | C | D | ||
| B | C | ||||
| C |
This will find the correct value in a maximum of comparisons with N being the length of the list, as shown in the above example as it took steps to find the position. Obviously this is worst case scenario and could only take 1 iteration if the required element is in the middle.
Grover’s Algorithm
Grover’s Algorithm 6 is an algorithm to find an object in an unordered list. It works by performing a Hadamard transform on the Qubit, turning it into multiple states with equal probability. For example, for 3 bit strings it would produce the superposition listed below:
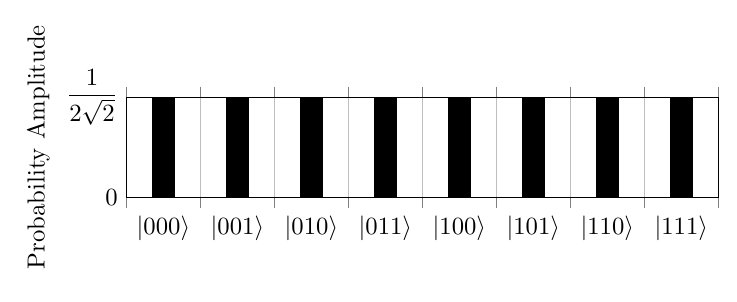
A function called the quantum oracle then looks at the state and turns the probability amplitude of the desired section negative. It does this through the process where f(x)=1 on the part of the superposition related to the desired element and f(x)=0 otherwise. More precisely, this creates the superposition The consequence of this is that a negative value will be returned when f(x)=1 and a positive value will be returned when f(x)=0.
This process will inverse the probability amplitude of the desired element, resulting in the state below attempting to search for .
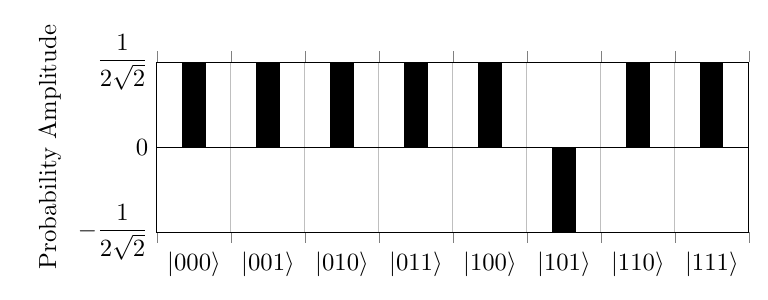
After this, the states are then increased based on their difference from the mean and decreasing the amplitude if the difference is negative, resulting in a higher probability for the desired element.
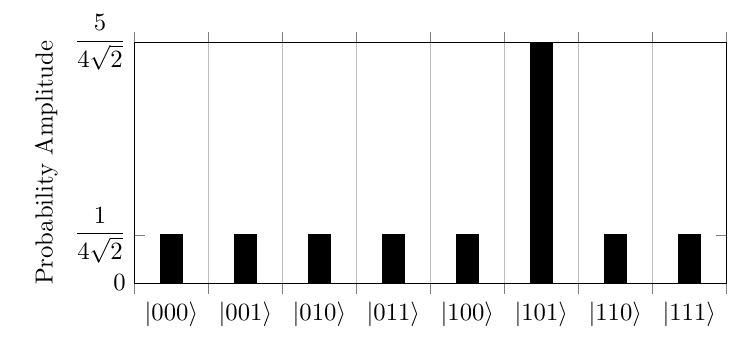
After one run this has a probability of the desired element being measured of , this puts the answer at a 78 probability of being correct when measured. In order to increase accuracy, this process is run times where N is the string length. For this example it would be times. This would mean that another loop of the inversion around zero, followed by the transformation around the mean, would be required to improve it to a suitable level of accuracy. This would then result in a probability amplitude of for the correct element, giving a probability of 95, a much better success rate making the algorithm more reliable.
Grover’s Algorithm compared to binary search
The main advantage of Grover’s Algorithm is that it can work on unordered lists, meaning that unlike binary search the list does not need sorting before an element can be found. The major advantage of this is that it does not also require a sorting algorithm and so is a much quicker option, meaning for larger databases it could be far superior. For large databases the extra storage required to hold the sorted data could mean that in binary search there would be a significant increase in storage costs as their requirements would in effect double if the data was not wanted to be stored in a sorted form. Another advantage of this is that the order of the data is often very important, and so by sorting it, the importance of the data is then lost.
The advantages of binary search are that it is a much quicker system to implement and is currently used in many facilities. This is because binary search can run on a classical computer, which is much cheaper both to buy and run than the quantum computer needed for Grover’s algorithm.
Another advantage of binary search is that it can be used on explicit databases (databases spread over multiple storage areas) 7 whereas Grover’s algorithm cannot. This means that it is limited to a file stored in one place, vastly limiting its capability, as most large databases (an area where Grover’s algorithm would be useful) are spread over multiple servers.For example, the millions of servers used by Google because it is impractical to store all the information in one place due to its size. Storing all the data in one place also reduces security and increases the impact of outages.
Binary search will also always give a correct answer, as opposed to the 90%-100% accuracy of Grover’s algorithm. This could be a large problem for large firms as a 10% failure rate over millions of searches would be unacceptable and so would mean that a classical algorithm would be the only option.
Factoring Algorithms
RSA Encryption
The main use of factoring numbers is in encryption, this is because many
encryption systems work on the factors of large numbers, I will explore
this with the example of RSA. RSA encryption works by multiplying two
large prime numbers together, this creates the number, n. This n is then
used to encrypt a message using the form where e is an
encrypting value. This is then decrypted using . A value
denoted as is a value based on the factors of n found by
where p and q are the factors. This value of
is then used to find e as it is any number less than n that is
not a factor. The value of d is then found using
where k is the first integer that makes d
an integer value.
RSA can be broken by finding the prime factors of n. This then allows
for to be found, allowing for d to be found, as shown above.
Then with the message,E,the decrypting value, d, and n the message can
be decrypted.
Quadratic Sieve
The quadratic sieve 8 is a classical algorithm used to factor numbers, it is performed by expressing the number to be factorised as the difference of two squares. Starting at and increasing the value of x until as below in factorisation of 989
| x | y | |
|---|---|---|
| 32 | 35 | 5.916 |
| 33 | 100 | 10 |
Obviously, not all iterations of this will be as quick but this shows that is equal to 989, the factors can then be found from 33+10=43 and 33-10=23. However, this will not work for all numbers. Factors can also be computed from values and that are not square numbers but multiply together to give a square number and the corresponding and . With A being and B being The GCD of (A+B, N) and (A-B, N) are factors.
Shor’s algorithm
Shor’s algorithm 9 is a quantum algorithm which also factorises numbers, however it performs it through a different method to the quadratic sieve. The first task is to find the period of where x is any number, 2 in my example. A is then increased from 0. n is the number to be factored. This will then create a list of numbers when performed and the period is found where the pattern repeats itself. In my example I tried to factor 989, as also shown in the quadratic sieve section. This results in a period of 154. Another number is then calculated by dividing the period over 2, called z in the formula then doing , working to being which results in y=300. From this number the GCD of (y+1,n) and (y-1,n) is calculated, these are easily calculated with Euclid’s algorithm, a classical algorithm, demonstrated below, trying to calculate GCD(301,989) and GCD(299,989). For example for 301 and 989:
When the number is added, the greatest common divisor will be the number at the end above, in this example 43. Doing this again for the other two numbers gives 23, these two numbers are the prime factors of 989. This is how it is performed classically, however when trying to find the period of large numbers takes too much time. Shor’s algorithm takes the number to be factored (N), and a random number (A) which is not a factor of N (GCD(N,A)=1). Another number, n, is chosen which dictates the size of the register, the larger this is the greater the time taken but the greater the accuracy. For this example N will be 39, A will be 7 and n will be 10. q is so in this case it is .
The algorithm is started in the state , the QFT (Quantum Fourier Transform) is then applied to the first Qubit, changing it to the state:
So with the numbers used in the example it is
Now is calculated and put in the second register, in Shor’s algorithm is . This then creates the state
The second qubit is then measured, this causes it to collapse to one state, meaning that the state will only include instances where f(x)=y, with y being the measured value. This now makes it easier to find the period, as the difference between values in the state is the period. The inverse QFT is then applied to this state.
This transformation then leads to a distribution of values with some having higher probability than others. The most likely values, divided by q, will approximately give a fraction, whose numerator is the period. For the numbers given above a likely value is 85. This is then divided by to give a fraction. This fraction is then converted, by continued fractions, into a number with a numerator of 1. This will give , giving the period of 12.
This period is then used in the formula which is the GCD of (25-1,37) and (25+1,39) are then found which are 3 and 13, which are the prime factors of 39.
Shor’s algorithm compared to Quadratic Sieve
For the example of factoring a larger number, for example 792347. Shor’s algorithm runs in time. This means that it will run in 68 time units. However, the quadratic sieve runs in time which would mean it would run in time units. This difference is because quadratic sieve runs in exponential time, whereas Shor’s algorithm runs in log time, meaning that as the number gets larger the difference in speed for Shor’s will be less than the difference for the quadratic sieve. Factoring becomes interesting regarding cryptography, this is because one of the most popular encryption methods is RSA. The current largest RSA number is RSA-2048, this is 2048 bits, equal to 617 digits. Using general number field sieve, the fastest algorithm for strings over 100 digits long, the time taken would be units. This is much longer than the run time for Shor’s algorithm for that number, which would be 40884 time units. The potential of Shor’s algorithm could mean that current cryptography systems will be obsolete as the security of RSA comes from the fact that the numbers can’t be factored. Supposing that the time units were seconds, the classical algorithm would take longer than the life of the universe as it would take years and the life of the universe is years. Comparing this to the run time of Shor’s algorithm which is 11 hours, it is easy to see the danger that Shor’s algorithm poses to existing encryption.
Conclusion
In conclusion the physics of quantum computers allow for superior computation to classical computers, but they come with the trade-off of increased manufacturing costs, increased power consumption and increased space requirements compared to a classical computer
Due to the increased popularity and reduced complexity of classical computers compared to quantum computers, how they work is much more widely known. This allows for far more people to be able to work on them, making it a better choice for companies to use them.
Quantum algorithms allow for data to be processed much faster than classical algorithms, however there is currently only a few available algorithms, meaning the utility of quantum computing is not yet fully realised. Quantum algorithms also are only superior to classical algorithms when processing large values, meaning that they wouldn’t provide any noticeable benefit to domestic consumers and may even perform worse than classical computers, whose main use is lots of short processes.
Currently quantum computers are only experimental, but some large companies, such as NASA, have bought a quantum computer in order to see what practical uses they can offer. However, companies such as Google may soon be able to find a practical use for them, for example, improving the speed of their search results, meaning they would be able to reduce the number of traditional servers, saving both power and space.
Without any breakthrough development in cooling technology, or a way to operate a quantum computer at room temperature, it is unlikely that quantum computers will be used directly by consumers in the foreseeable future. Instead they will be used as a replacement for supercomputers due to their reduced space and power requirements for the same performance. Therefore the only interaction consumers will have with quantum computers will be over the internet. This is because they have the power to increase the speed and accuracy of image recognition, search speed and may also revolutionise the encryption industry.
I believe I have achieved what I have set out to achieve as I explored the utility of quantum computers and their limitations. I think overall quantum computers could be better than supercomputers but it is unlikely they will be used, widely in the consumer market without further advances in technology.
Footnotes
-
Moore, G. 1998. Cramming more components onto integrated circuits. Proceedings of the IEEE, 86(1), p.82–85. ↩
-
Steane, A. 1997. The ion trap quantum information processor. Applied Physics B: Lasers and Optics, 64(6), p.623–643. ↩
-
Steane, A. 2012. Introduction to Ion Trap Quantum Computing. University of Oxford - Department of physics. ↩
-
Weisstein, E. 2002. Pauli Matrices. MathWorld–A Wolfram Web Resource. ↩
-
Deutsch, D., and Jozsa, R. 1992. Rapid solution of problems by quantum computation. In Proceedings of the Royal Society of London A: Mathematical, Physical and Engineering Sciences (pp. 553–558). ↩
-
Grover, L. 1996. A fast quantum mechanical algorithm for database search. In Proceedings of the twenty-eighth annual ACM symposium on Theory of computing (pp. 212–219). ↩
-
Viamontes, G., Markov, I., and Hayes, J. 2005. Is quantum search practical?. Computing in science & engineering, 7(3), p.62–70. ↩
-
Pomerance, C. 2008. Smooth numbers and the quadratic sieve. Algorithmic Number Theory, Cambridge, MSRI publication, 44, p.69–82. ↩
-
Shor, P. 1999. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. SIAM review, 41(2), p.303–332. ↩